
老师给了强化学习的方向,发了个网课看,把第一讲的笔记整理了一下,然后确信了这个方向属实很难…
Introduction to Reinforcement Learning
1.About RL
多学科交叉领域
与监督学习、无监督学习一样是机器学习的一个分支
Characteristics:
没有supervisor signal,只有reword signal,agent通过试错的方法
与环境交互
反馈有时是delay的
处理的sequential的数据,与时间相关
agent动作影响收到的数据
2.Problem:
给定agent(智能体)一个state(状态),agent作出action(动作),作用在环境上,会返回reward转移到下一个状态,the agent is to maximize the cumulative reward(最大化累积奖励回报)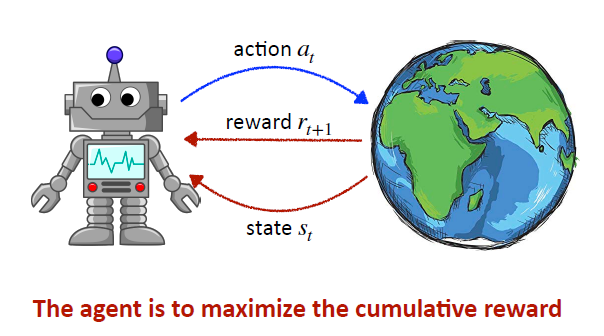
能够用最大化期望的累积回报来描述,这样的问题都可以用RL来解决。
3.Inside An RL Agent:
Policy:根据s输出动作a
Value function:衡量状态的好坏
Model:环境的模型(未知的,通过与环境交互学习模型)
Categorizing RL Agents:
Value based:只学习value function
Policy based:只学习policy
Actor Critic:两者都学
Model free:不学习model(上面三种都是)
Model based:学习model
4.Markov Decision Processes
描述了一个RL的学习环境,环境是全观察的(环境完全已知)
几乎所有的RL问题都可以转换成MDP
MDP中所有的states都有“Markov”性质(MDP的策略完全取决于当前状态)
一个MDP就是一个五元组<S,A,T,R,γ>
Policy
一个policy π是给定状态采取动作的概率分布
Value Function
state-value function
vπ(s):从state s开始,按照policy π,得到一个期望的reword(E)
action-value function
qπ(s,a):从状态s开始,选取动作a,然后按照policy π,得到一个期望的reward(E)
Optimal Value Function
the optimal state-value function
the optimal action-value function
Optimal Policy
if vπ(s)>=vπ’(s), define π >= π’
所有的optimal policy不一定只有一个,但optimal value function都是相同的
如果知道the optimal action-value function,则可以得到optimal policy
Value-based Methods
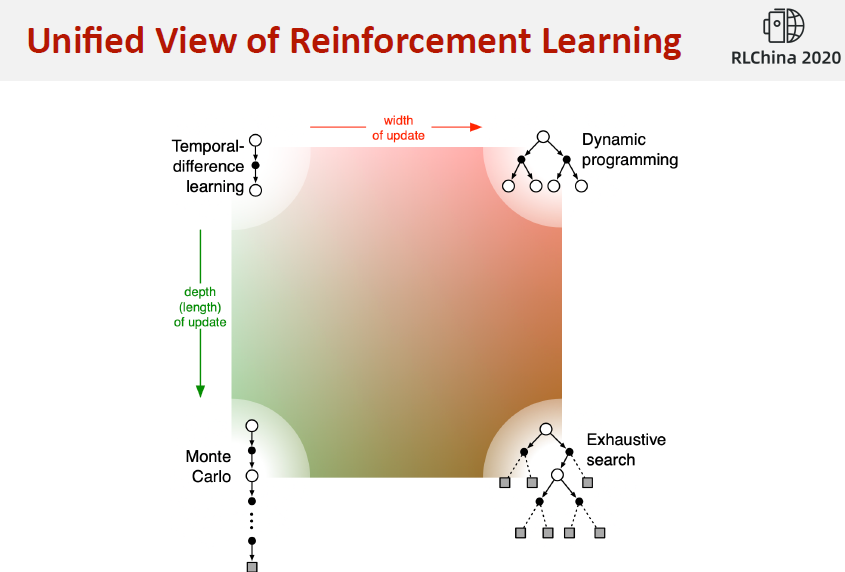
1.Dynamic Programming
DP 知道MDP的全部知识,planning in an MDP
For prediction:在已知模型的基础上判断一个策略的价值函数,并在此基础上寻找到最优的策略和最优价值函数
For control:已知模型,直接寻找最优策略和最优价值函数
Policy Evalution
problem:计算给定策略π的value function
solution:iteration of Bellman Expectation backup(反向迭代应用Bellman期望方程)
Policy Evaluation in Gridworld

迭代计算公式没搞明白
动态规划寻找最优策略之policy evaluation(策略估计)
Policy Improvement
Policy improvement的作用是对当前策略 π 进行提升,先讨论一个简单情况下的策略提升,再讨论全局意义上的策略提升。
Policy Iteration
Value Iteration
Generalized Policy Iteration
Contraction Mapping
听到这里已经懵逼了,完全是念ppt(或者说翻译ppt…),感觉根本不是零基础入门的课..
……
DP Summary
每轮迭代复杂度O(mn^2),m actions、n states
维度爆炸的问题
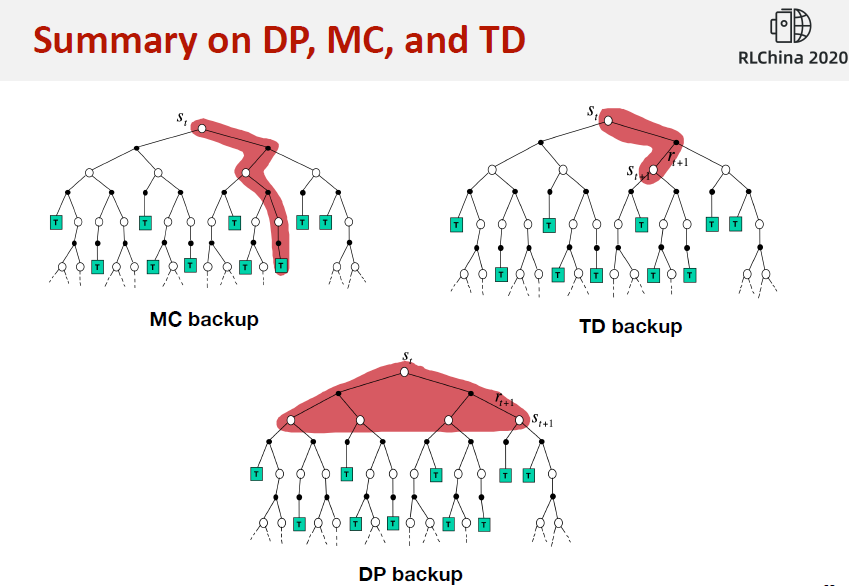
2.Monte Carlo
蒙特卡洛强化学习指:在不清楚MDP状态转移及即时奖励的情况下,直接从经历完整的Episode来学习状态价值,通常情况下某状态的价值等于在多个Episode中以该状态算得到的所有收获的平均。
完整的Episode 指必须从某一个状态开始,Agent与Environment交互直到终止状态,环境给出终止状态的即时收获为止。
……
3.TD Learning
时序差分学习简称TD(Temporal-Difference Learning)学习,它的特点如下:和蒙特卡洛学习一样,它也从Episode学习,不需要了解模型本身;但是它可以学习不完整的Episode,通过自身的引导(bootstrapping),猜测Episode的结果,同时持续更新这个猜测。
4.Off-policy Learning
Q Learning
5.DQN and its variants
Deep Q Network